2. Select one of the three statistical methods: log-likelihood, mutual information, and chi-square, or select “Raw Frequency” if you want to see only frequency of occurrences. The default is log-likelihood.
3. Select the span ranged from 2 to 5. The number indicates the number of words to look for collocations. For example, if “2 words” is selected, the program will search for collocations of two-word chunks. If “3 words” is selected, the program will search for collocations of three-word chunks.
4. Set all the options. First, set the direction for searching collocations by selecting “Option-Search Collocates on”. If “Left Side” is selected, the program looks for all collocates that occur before the keyword. The default is “Both Sides”. Select the minimum frequency of n-word collocations. This will instruct the program to look for only collocations that occur at least N times, where N is the number specified. Then, select the statistical significance at the level of “p > .005”, “p > .05”, or “all occurrences”. Set the maximum number of collocations to be extracted. The default is “500” items. When searching for 2-word collocations, users can specify the distance between the two words. If set as “2”, the two words are separated by one word. This option is provided because collocations sometimes can be separated by other words, such as “hold (oppositional) views”, “hold (a similar) view”, etc. The last option, “Ignore Header Tag”, is selected by default. This will instruct the program to ignore all information in the header tag <Header> ….. </Header>, which is encoded in sgml and xml files. (Information in the header tag is usually not the contents, but the bibliographic and encoding information.)
5. Specify the search. There are two ways to specify the search. The first one is to specify the keyword (“Search – Keyword”) to be searched. The second way is to search for all 2-word collocations “Search - All 2-word Collocations”. When searching for all 2-word collocations, users can specify the distance between the two words, as explained before.
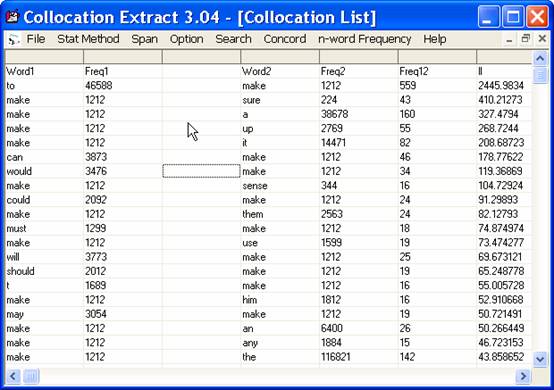
6. When searching is finished, the collocation windows will display the list of collocates that co-occur with the keyword, sorted by order of significance. If two-word collocation is searched and the distance of the two words is greater than one, a number of underscore symbols, “_”, will be marked between the two words to indicate the distance. Users can save the collocation list by selecting “File-Save Colloc List”. The output will be saved as a text file with tab delimited between each column. The output file then can be imported into the Excel program for further use.
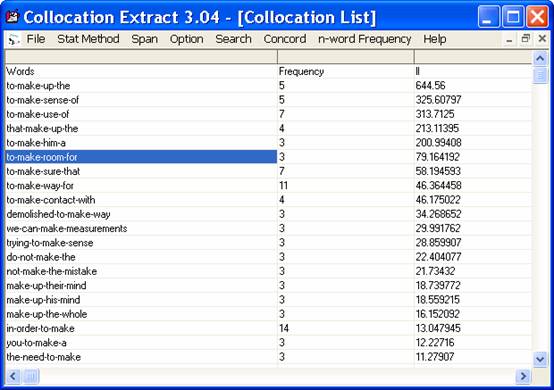
7. If users want to see the contexts of a particular word, they can click on that word, and select the menu bar “Concord”. The specified word and its collocate will be shown. Use “*” to mark for all words. Select the order of occurrences, and the number of characters for left and right contexts.
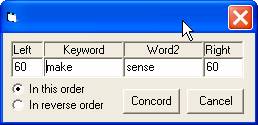
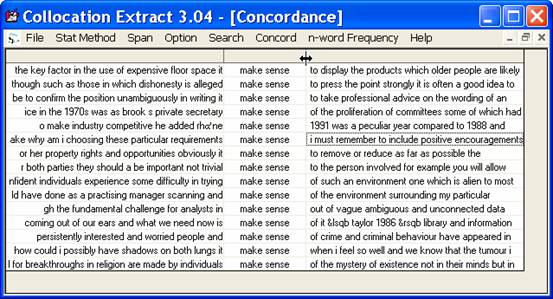
8. The concordance output will be shown in three columns. Users can save the result for further use by selecting “File - Save Concordance”. Although this concordance feature is made available in Collocation Extract, it is suggested that concordance software should be used, if users want to work extensively on concordance results. This feature is provided for users just to take a quick look at the contexts.
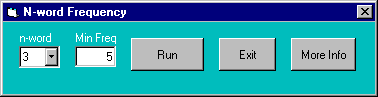
9. The program can list sequences of n-words from the corpus and the frequency of occurrences. Click on “n-word Frequency” menu, and specify the number of word sequence and the minimum frequency. For example, if n-word is set as “3”, and “Min Freq” as “5”, the program will list all sequences of three-word chunks that occur at least 5 times in the corpus. The result of this search will not be shown on the screen. It will be saved as a text file.
Copyright 2000-4. Wirote
Aroonmanakun.
Dept. of
Linguistics,
Chulalongkorn
University